Live demos
Six walkthroughs. Real data.
Each demo is a full interactive investigation — dollar-for-dollar, hop-for-hop. Open one and replay a real case through time.
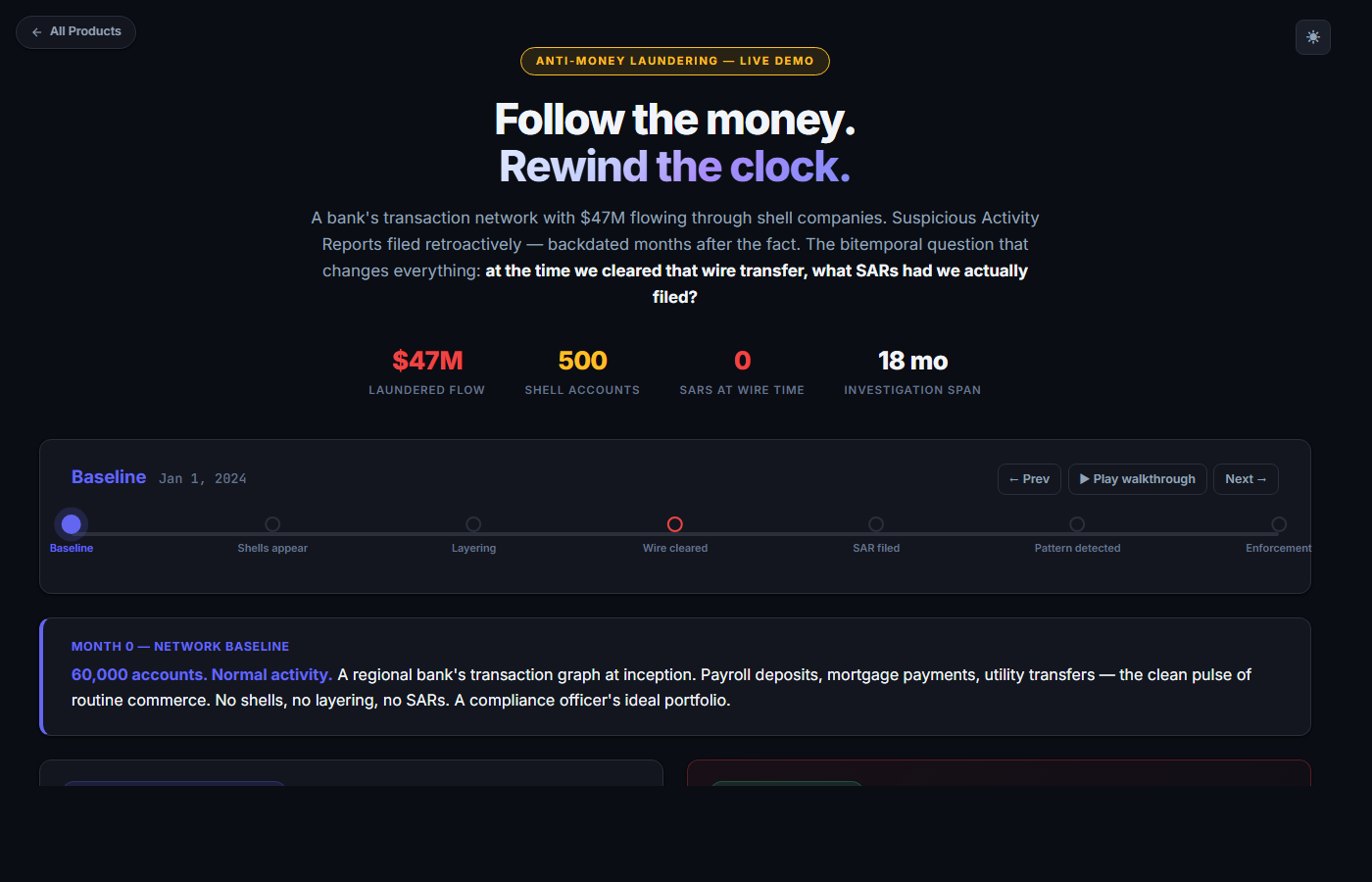
Anti-money laundering
Follow the money. Rewind the clock.
Open demo
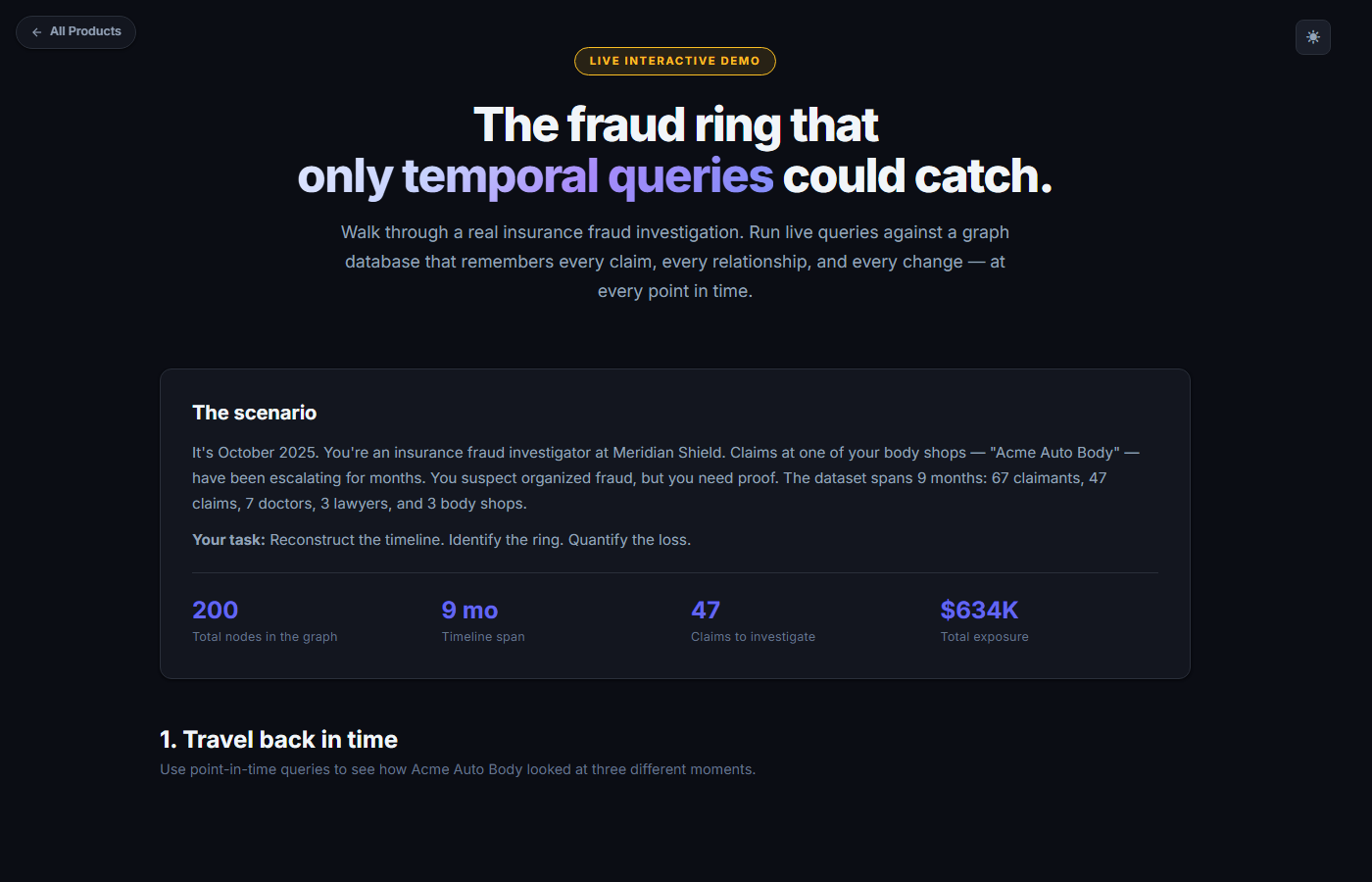
Insurance fraud
The fraud ring only temporal queries could catch.
Open demo
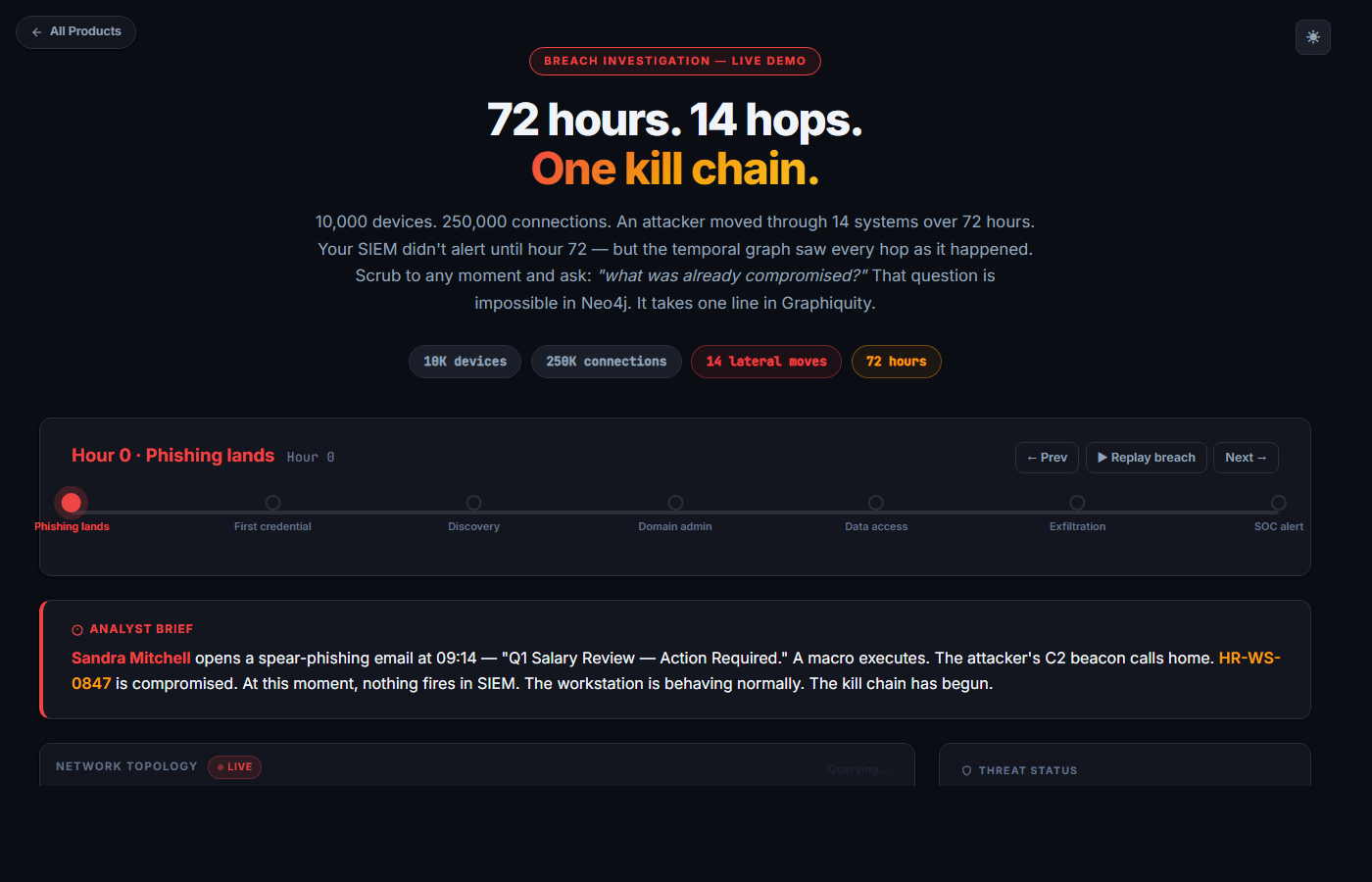
Breach investigation
72 hours. 14 hops. One kill chain.
Open demo
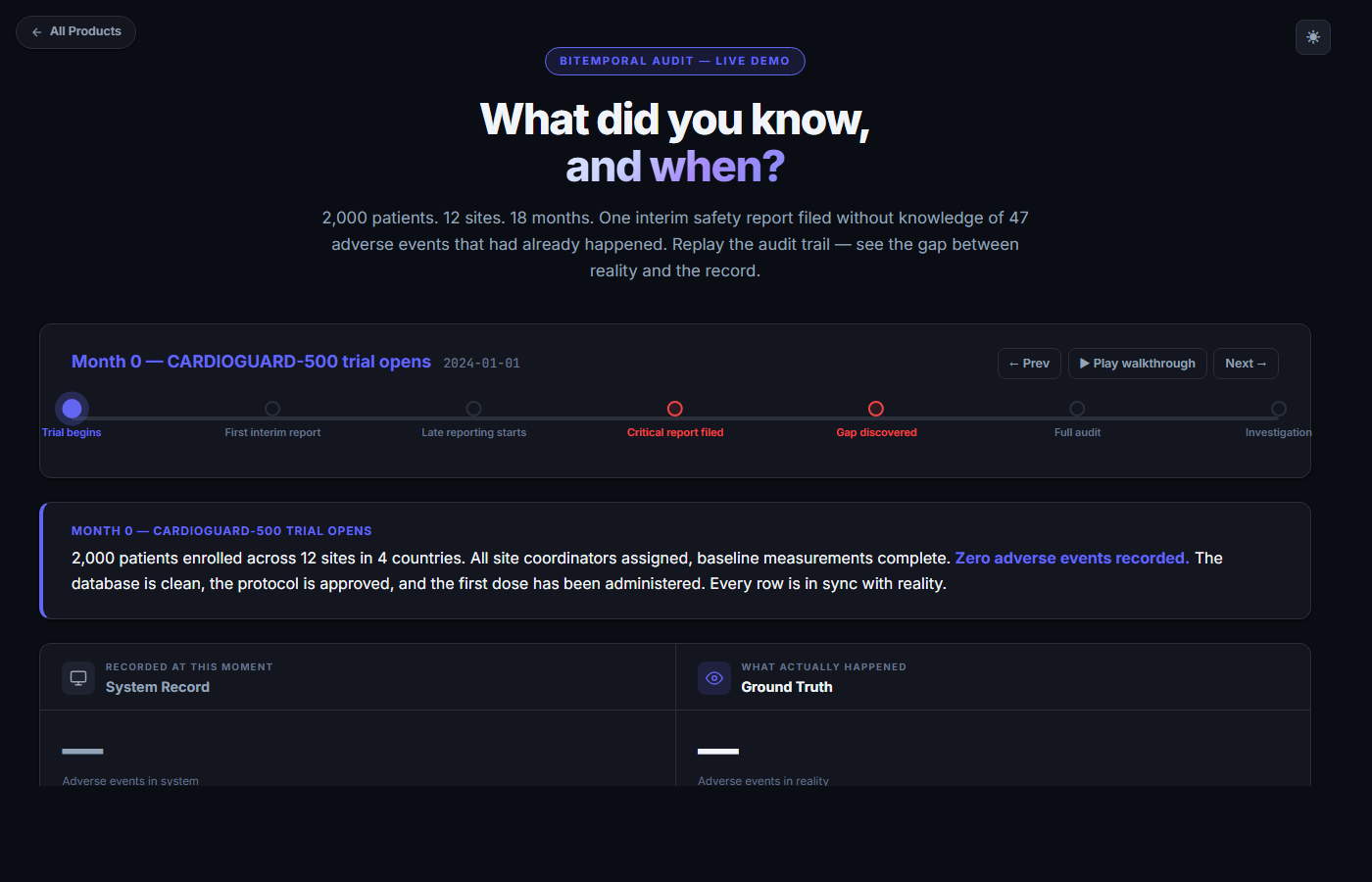
Clinical trial audit
What did you know, and when?
Open demo
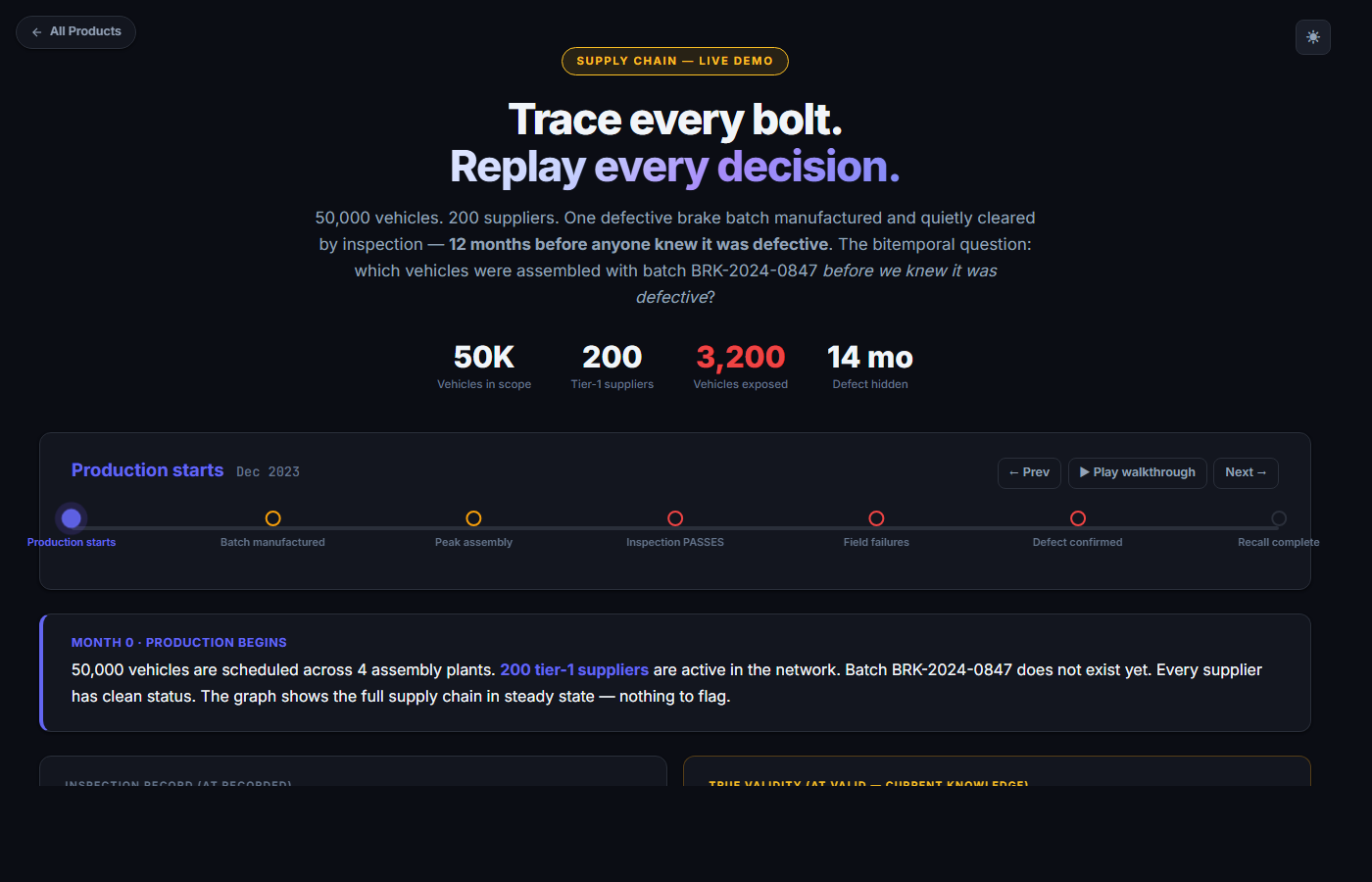
Supply chain recall
Trace contamination across 6 supplier hops.
Open demo
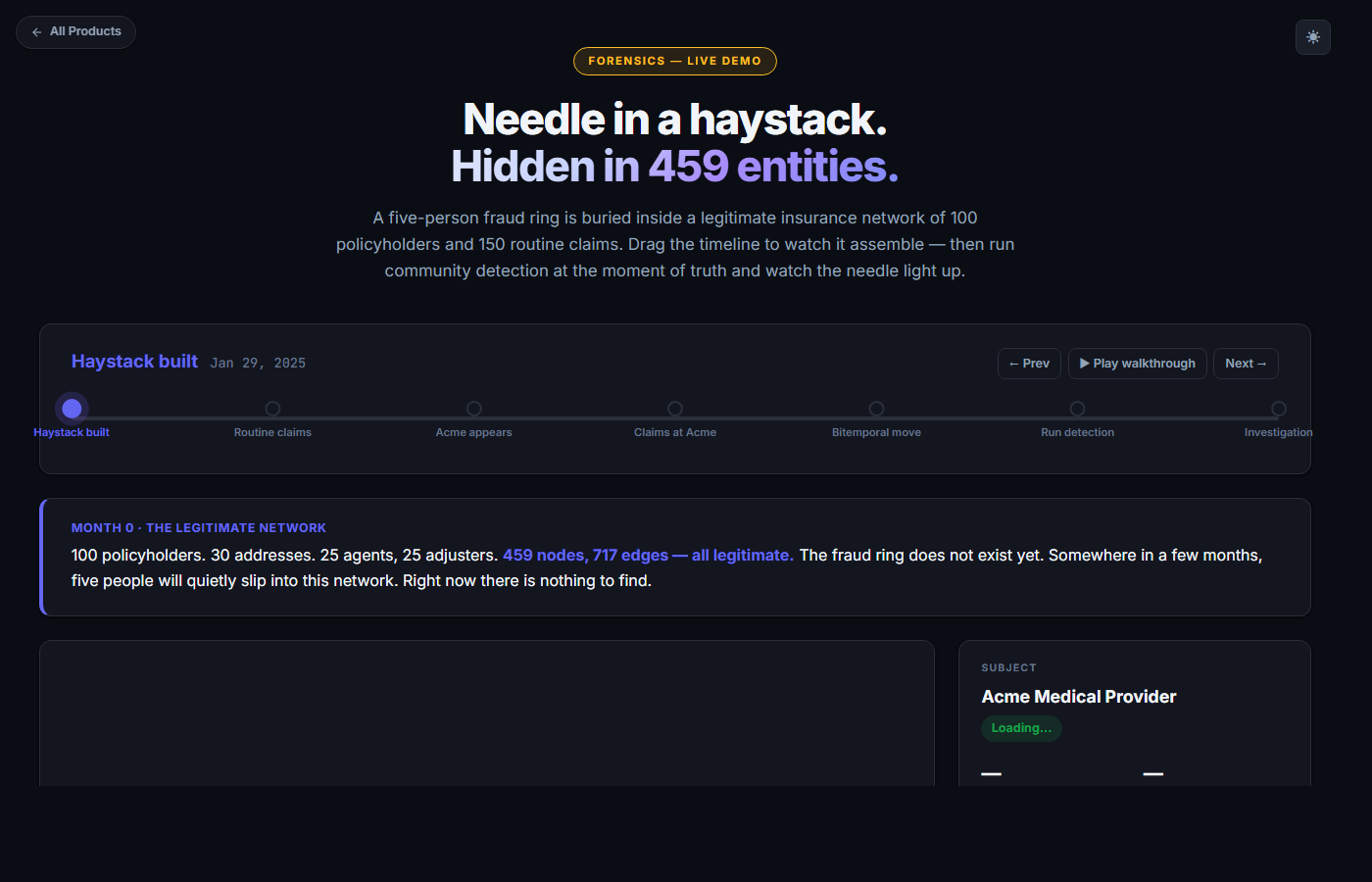
Digital forensics
Chain of custody. Reconstructed by query.
Open demo